spark on yarn有两种模式。在cluster模式下,driver是运行在ApplicationMaster上的,而client模式下则是运行在用户提交spark任务的那台机器上。
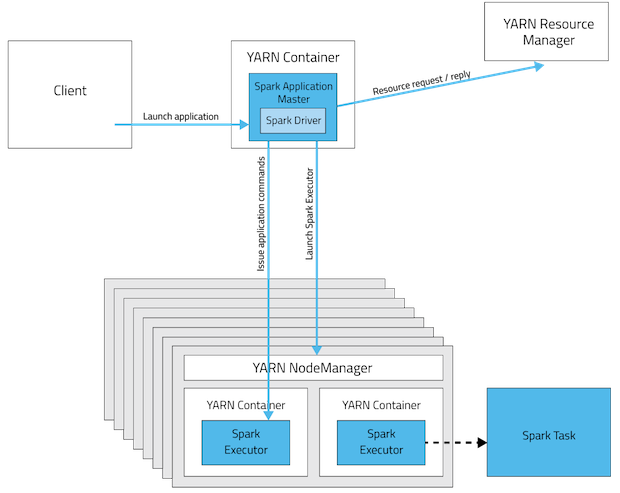
Yarn和standalone的架构其实是对应的,下表给出了两者的对应关系
| Standalone | YARN |
|---|---|
| Client | Client |
| Master | ApplicationMaster |
| Worker | ExecutorRunnable |
| Scheduler | YarnClusterScheduler/YarnScheduler |
| SchedulerBackend | YarnClusterSchedulerBackend/YarnClientScheduleBackend |
这一篇讲的了流程http://blog.itpub.net/29754888/viewspace-1815323/
先讲一下cluster模式
spark提交的入口在org.apache.spark.deploy.SparkSubmit。prepareSubmitEnvironment来根据提交方式初始化,比如设定taskScheduler的类型是YarnClusterScheduler,schedulerBackend的类型是YarnClusterSchedulerBackend。之后如果是cluster模式,会通过反射最终回来到org.apache.spark.deploy.yarn.Client,最终调用client.run函数向yarn提交一个application。提交的application时设置了AM类型是org.apache.spark.deploy.yarn.ApplicationMaster。这个am启动时会调用main函数然后调用到run函数。进行相关设置后cluster模式下run函数会调用rundriver,rundriver代码如下
|
|
- 首先ApplicationMaster初始化时会接受一个YarnRMClient的参数,这个类主要负责注册application相关,是对AMRMClient的wrapper。
- userClassTread是一个新线程,他里面启动Spark driver,rundriver最后会等待这个线程完成,完成后即表示着注册之后就会等待userClassThread完成。
- waitForSparkContextInitialized是一个很hacky的函数,它主要是获取SparkContext,这里的sc我理解是userClassThread创建的。
- runAMEndpoint函数主要启动了一个AMEndpoint,这个endpoint负责处理,RequestExecutors,KillExecutors,GetExecutorLossReason几个消息。
- registerAM函数会创建allocator这个成员变量。allocator负责和resourceManager交互获取资源。在rundriver中会先调用一次
allocator.allocateResources(),如果第一次rm给的资源没有满足,reporterThread会继续重试请求资源。下面这张图很好的说明了applicationMaster如何一步步构造出allocator并与rm通信的。 
这里稍微展开一下allocator,看看他如何启动executor。在allocateResources中,他会向rm请求资源。当收到资源后,他会调用handleAllocatedContainers函数,该函数会按照host,rack,其他的空间亲和顺序依次匹配资源并在上面启动指定数量的container。首先allocator会调用matchContainerToRequest来更新containersToUse,remaining还有amClient中下次需要申请的资源的队列(amClient.removeContainerRequest(containerRequest)),也就是调用matchContainerToRequest来更新资源需求的记录。之后对于所有在containersToUse中的资源,调用runAllocatedContainers(),对于每个资源启动一个ExecutorRunnable,目前executorRunnable对应一个org.apache.spark.executor.CoarseGrainedExecutorBackend。
这里有一张图展示了ApplicationMaster中各个组件的关系:

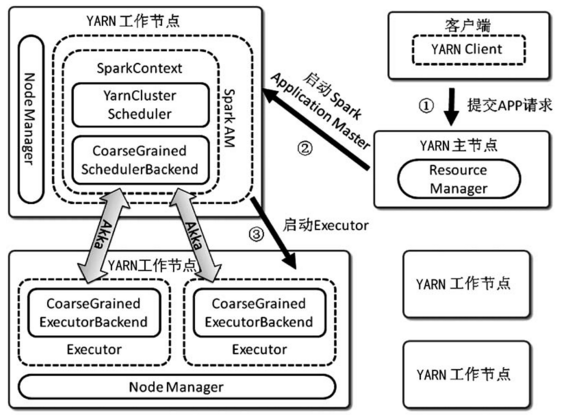
最后附一张cluster模式下整体的图:
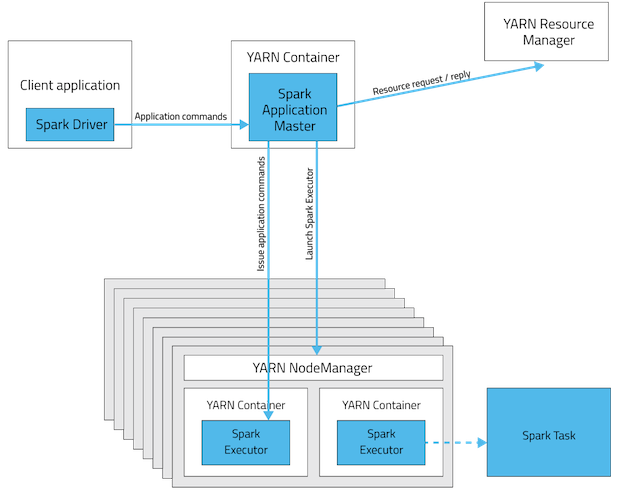
再看一下yarn client模式
下图是一个spark在yarn上以client模式运行程序的流程。
client模式主要是讲driver运行在client端,他和cluster模式有一下几个不同:
- client的taskscheduler和backend分别是yarnScheduler和yarnClientSchedulerBackend。
- YarnClientSchedulerBackend里面会启动一个client,它里面会启动一个yarnClient。通过这个yarnClient,我们可以给resourceManager提交ApplicationMaster。
- client的ApplicationMaster调用的是runExecutorLauncher。同时,注意到因为在AM上其实是通过jps查看类名来分辨AM的类型的,所以在ApplicationMaster中既有
object ApplicationMaster又有object ExecutorLauncher。
参考文献
本文采用创作共用保留署名-非商业-禁止演绎4.0国际许可证,欢迎转载,但转载请注明来自http://thousandhu.github.io,并保持转载后文章内容的完整。本人保留所有版权相关权利。