standalong模式
stangalone模式是spark自己部署自己在集群上的一个模式。

其中client模式下driver运行在提交任务的机器,cluster模式下运行在cluster内部的某个worker上,只能独自运行。executor不是在worker启动时启动的,而是一个新的application来时才启动的(master调用startExecutorsOnWorkers())。
集群启动流程
集群启动主要是启动master和worker
|
|
启动过程中,worker需要向master注册自己,并且定时发动心跳,具体实现在org.apache.spark.deploy.master和org.apache.spark.deploy.worker两个类里。启动时worker会调用registerWithMaster()向master注册,并且通过heartbeat定期与master通信。
任务提交
driver是一个hosts SparkContext的进程,是整个程序的入口,下面上一张driver的架构图

启动一个任务的具体流程是这样的:
- driver创建一个SparkContext,进而启动一个scheduler(一般是TaskSchedulerImpl)和一个backend(一般是StandaloneSchedulerBackend)。StandaloneSchedulerBackend的StandaloneAppClient向master发起请求注册一个application(registerWithMaster函数)。该函数会向Master发送一个RegisterApplication的rpc请求
Master收到请求生成一个Application,同时做了以下两件事情
- 向Driver发送一个RegisteredApplication消息。Driver收到这个消息以后会开始监听这个app
- 调用scheduler函数给application分配资源:
- 如果是cluster模式,则通过
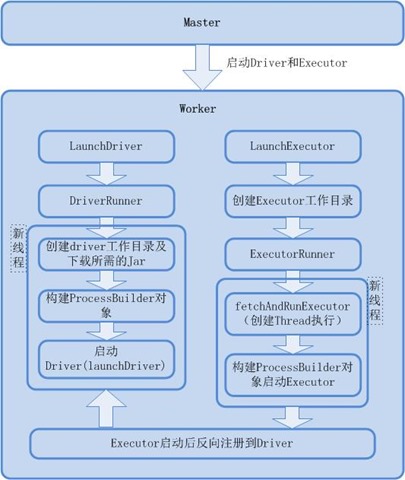
launchDriver(worker: WorkerInfo, driver: DriverInfo)函数将worker和driver联系起来,发送LaunchDriver(driver.id, driver.desc)消息给worker。worker收到LaunchDriver生成一个DriverRunner对象并启动。如果是client模式,schedule对于的waitingDrivers中的driver为空,不会调用launchDriver在worker上生成driver。 - 调用
startExecutorsOnWorkers()进而调用launchExecutor()发送LaunchExecutor给工作节点。默认情况下使用spread out模式,将executor尽量分配到多个worker上
- 如果是cluster模式,则通过
- worker收到launchExecutor消息启动Executor。Worker创建一个ExecutorRunner线程,ExecutorRunner线程会调用fetchAndRunExecutor函数给Executor创建新的进程。
- Executor(CoarseGrainedExecutorBackend.run())启动后会根据driverUrl向Driver注册自己。
- Driver的DAGScheduler解析作业并生成相应的Stage,每个Stage包含的Task通过TaskScheduler分配给Executor执行。 所有stage都完成后作业结束。
 \
\
任务提交这里参考了
- Spark源码学习(2)——Spark Submit(cluster)
- Spark系列(八)Worker工作原理
- client模式参考文献
- Spark系列(四)整体架构分析
- 应用执行过程分析 启动过程讲的最清楚的一篇
容错
worker退出
worker意外挂掉或者退出以后,worker上的所有Executor都会被kill或者丢失。此时worker与master间的heartbeat也不存在了,master会觉察到这一异常,从而会将这些executor失败的事情告诉driver
Executor退出
- ExecutorRunner会注意到异常,通过ExecutorStateChanged汇报给master
- Master要求worker重启Executor
- worker收到指令重启Executor
Master退出
在设置了Zookeeper和standby master的前提下,集群也可以恢复master失败。利用ZooKeeper可以提供leader的选举以及一些状态的存储,在集群中可以启动多个Masters来连接到相同的ZooKeeper实例。其中一个会被选举成“leader”,其他的仍旧处于standby模式。如果当前的leader死掉了,另一个Master会被选举出来,恢复之前的那个Master的状态,然后恢复调度。整个恢复过程需要花费1到2分钟时间。注意,这个延迟只会影响到新的应用程序–在故障转移期间,已经运行的应用程序不会受到影响。
supervise参数
standalone集群模式支持自动重启你的应用程序,如果它以非0的退出代码退出。要使用该功能,当启动你的应用程序时,你可能需要在spark-submit中传入 --supervise。然后,如果你想要杀死一个重复失败的应用程序,也许可以这样做:
|
|
参考文献
本文采用创作共用保留署名-非商业-禁止演绎4.0国际许可证,欢迎转载,但转载请注明来自http://thousandhu.github.io,并保持转载后文章内容的完整。本人保留所有版权相关权利。
本文链接:http://thousandhu.github.io/2016/10/25/spark2-0-standalong模式部署/