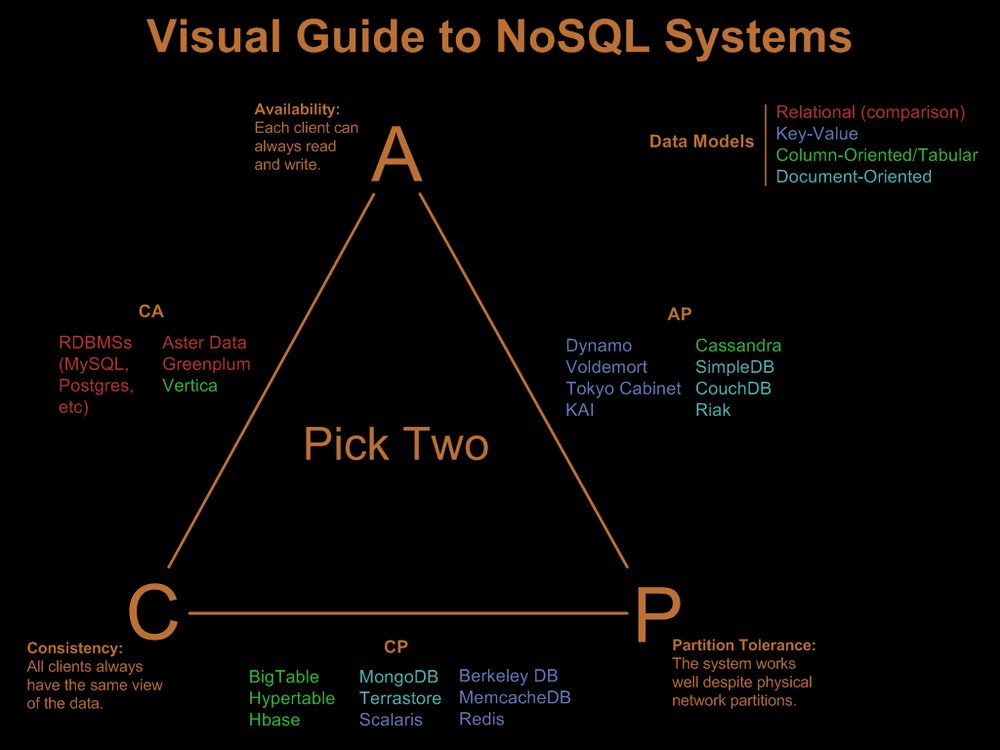
| CP | AP | 优点 | 缺点 | 适用场景 | 不适用场景 | |
|---|---|---|---|---|---|---|
| 键值数据库 | Berkeley DB / MemcacheDB / Redis / Scalaris | Riak / Dynamo / Voldemort | 1.数据结构支持广泛,值可以是二进制,文本等各种格式。 2.凯苏查询 | 1.只能根据key来搜索,无法根据值来搜索。2.只有针对单行的一致性。乐观写入实现成本高 | 1.存放会话信息 2.用户配置信息 3.购物车数据 | 1. 需要在数据间建立联系 2.含有多项操作的事务 3.按值查询数据 4.操作关键字集合 |
| 文档数据库 | MongoDB / Terrastore | SimpleDB / CouchDB | 1.可以只更新部分文档 2.支持子域查询 | 查询性能不高 | 1. 事件记录 2. 内容管理系统和博客系统 3. 网站实时分析 4. 电子商务应用程序 | 1.包含多项操作的复杂查询(不适合跨文档的原子操作) 2.查询持续变化(结构变化)的聚合结构(查询语句随数据变化变化大) |
| 列族数据库 | BigTable / Hbase / Hypertalbe | Cassandra | 1. 半结构化,最适合用来分析庞大的数据集 2处理大量数据,应对极高写负载,高可用,支持跨数据中心 | 没有文档数据库灵活,功能局限 | 1. 事件记录 2.计数器 3内容管理和博客平台 | 1.需要ACID事务 2.查询模式经常变化 |
- CP - 满足一致性,分区容忍必的系统,通常性能不是特别高。
- AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
参考文献:NoSQL数据库的35个应用场景,使用键值类NoSQL数据存储时的数据建模,解读NoSQL数据库的四大家族
一些产品的一致性和读写性能是可以通过设置控制的。比如Riak可以参考这篇文章.
图数据库
Neo4J, Infinite Graph, HyperGraphDB, OrientDB
适用案例
- 互联数据
- 安排运输路线、分派货物和基于位置的服务
推荐引擎
不适用的场合
更新全部或某个子集内实体的场合
- 涉及整张图的操作
第12章 模式迁移
- 若要迁移关系型数据库等“强模式”的数据库,可将历次模式变更及其数据迁移操作保存于“版本控制序列”中。
- 因程序代码要依照“隐含模式”来访问无模式数据库的数据,故其数据迁移仍需谨慎处理。
- 无模式数据库亦可借用强模式数据库的迁移技术。
- 无模式数据库可使用“增量迁移”技术更新数据,以便在不影响应用程序读取数据的前提下,修改数据的隐含模式。
第13章 混合持久化
- 混合持久化旨在使用不同数据库技术处理多种数据存储需求。
- 混合持久化既可为企业中多个程序所用,也可以运用在单个应用程序中。
- 将数据访问封装成服务,可以减少数据库变动对系统其它部分的影响。
- 新增数据库技术会让编程和操作更复杂,所以要权衡引入新数据库带来的好处和引入它带来的复杂度的利弊。
第15章 选择合适的数据库
- 通过使用更符合应用程序需求的数据库来改善程序员的工作效率。
- 以能处理大数据量、降低延迟且增进数据吞吐量的某种技术组合来改善数据访问性能。
- 在决定使用某个NoSQL技术之前,一定要测试其是否如预期般改善了程序员工作效率和数据访问性能。
- 用服务来封装数据库,即能在需求变更或技术成熟后改换其所封装的数据库技术。可将应用程序各部分划分到不同服务中,以便为既有程序引入NoSQL数据库。
- 大部分应用程序,尤其是“非战略性的”应用程序,应该继续使用关系型数据库技术,至少在NoSQL技术环节尚未更加成熟时是如此。
参考文献

本文采用创作共用保留署名-非商业-禁止演绎4.0国际许可证,欢迎转载,但转载请注明来自http://thousandhu.github.io,并保持转载后文章内容的完整。本人保留所有版权相关权利。