容错机制
Yarn的荣作主要是ApplicationMaster,Nodemanager,Container和ResourceManager四个组件的容错。
- ApplicationMaster容错。ResourceManager会和ApplicationMaster保持通信,一旦发现ApplicationMaster失败或者超时,会为其重新分配资源并重启。重启后ApplicationMaster的运行状态需要自己恢复,比如MRAppMaster会把云翔状态记录到HDFS上,重启后从HDFS读取运行状态恢复
- NodeManager容错:NodeManager如果超时,则ResourceManager会认为它失败,将其上的所有container标记为失败并通知相应的ApplicationMaster,由AM决定如何处理
- container容错:如果ApplicationMaster在一定时间内未启动分配的container,RM会将其收回,如果Container运行失败,RM会告诉对应的AM由其处理。
- ResourceManager容错,因为RM是yarn架构中的一个单点,所以他的容错很难做,一般是采用HA的方式,有一个active master和一个standby master。active master挂了由standby补上。
resourceManager HA的原理
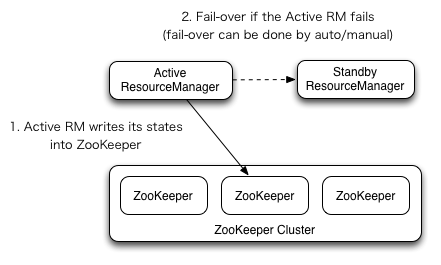
resourceManager的ha是一个active/standby模式。HA模式下,active resourceManager会将Application的状态,Application每次尝试(ApplicationAttemptId)的状态以及安全令牌相关的信息储存起来,如果active rm挂了则将standby切换成active。
HA需要在yarn-site.xml中进行相关配置,具体可以看文档。手动切换的话,使用命令yarn rmadmin。比如以下命令可以查看或者切换RM的状态:
|
|
自动切换的话网上很多资料都是说和HDFS类似,运用zkFailoverController。他大体的架构如下图。他的基本的实现思想是,所有ResourceManager启动后,将创建Zookeeper下的同一个目录,谁创建成功,则谁进入active状态,其他的自动转入standby状态。而当active RM失效时,standby rm自动转换成active

ResourceManager HA的实现
yarn ha的共享内存系统被抽象成RMStatStore。 底层采用不同的共享文件系统,比如zookeeper,NFS,HDFS等,不同的实现都要继承这个类,然后实现具体的save/load等功能。
RMStateStore这个类是一个service,并且维护了一个状态机。状态机其实只有两个状态Active和Fenced。如果state是active,那么他接收部分事件时就会调用指定函数更新具体app的状态。比如状态机生成时添加的这个transition
|
|
表示RMStateStore是active时如果收到了STORE_APP这个事件则调用StoreAppTranstion这个子类定义的transition。接下来看一下这个子类
|
|
这个store是一个RMStateStore,而其中storeApplicationStateInternal和notifyApplication实现和具体存储有关,比如在ZKRMStateStore中,这个函数实现了他如何存到一个zk的指定路径。在resourceManager中,RMStateStore存在rmContext中。
ResourceManager会把service分为两部分,activeService和adminService。activeService是诸如amLivelinessMonitor,amLivelinessMonitor这种集群中只需要一个处于活跃状态的service。而adminService主要是管理rm自身已经ha相关的service。只有处于active状态的rm会启动activeService,AdminService则是所有rm都会启动的。
在ha模式下,所有resourceManager启动后都会调用transitionToStandby()切换到standby状态,之后注册zk node并将第一个切换成active(不过切换成active的代码我没找到)。
AdminService中有一个EmbeddedElectorService,应该是和zookeeper一起选择active rm的服务。如何利用zookeeper实现ha我觉得可以新开一篇和hdfs的ha一起讲一下。
恢复状态是resourceManager在serviceStart的时候会判断是否需要恢复,如果需要则调用recover()函数从之前存好的RMState中取出相关信息进行恢复。
参考文献
- ResourceManagerHA官方文档
- YARN源码分析(三)—–ResourceManager HA之应用状态存储与恢复
- YARN ResourceManager HA配置详解
- Hadoop YARN单点故障解决方案(HA)介绍
本文采用创作共用保留署名-非商业-禁止演绎4.0国际许可证,欢迎转载,但转载请注明来自http://thousandhu.github.io,并保持转载后文章内容的完整。本人保留所有版权相关权利。
本文链接:http://thousandhu.github.io/2016/07/30/深入解析yarn架构设计与技术实现-Resource-Manager剖析4/