这篇文章是在阅读了spark streaming Programming Guide以后的一些总结。主要是spark streaming和spark的数据结构DStream和RDD的对比,以及DStream数据接收到发送到spark engine的一些细节。
Streaming 和DStream
spark streaming是一个流式的处理框架,通过从实时数据流接入数据,然后划分为小的批量传递给spark engine处理。

Spark streaming对这种持续数据做了一个高级抽象DStream(discretized stream,离散数据流)。在DStream里面就包含了一系列的RDDs。而作用于DSteam的算子都会被转化为对内部RDD的操作。作用在DStream上的操作,其实可以看做作用在其中每一个RDD的操作。和RDD类似,他也是先记录计算逻辑,直到遇到类似Dstream的action才进行实际操作。
Receiver
每个Dstream都对应着一个接收器Receiver。在spark streaming中,接收器都是长期运行的,在分配cpu是cpu core要大于接收器的总数,负责该应用只会接收数据而不会处理数据。Receiver除了原生的文件系统socker和akka actor以外还有一些是需要增加额外依赖的。比如kafka,flume的receiver。同时,也可以自定义receiver。
自定义Receiver主要就是实现onStart()和onStop()两个非阻塞函数。一般都是在onstart里面启动一个线程来读数据,读到的数据调用store()存到spart中。
transform
得到Dstream以后会对他进行一系列的transform,这里不具体讲transform有哪些,只是说一下transform有两个大类。一类就是普通的transform,比如map,flatmap等。另一类是基于窗口的transform,这种算子可以对于某一滑动窗口时间内的数据施加特定的transformation算子:
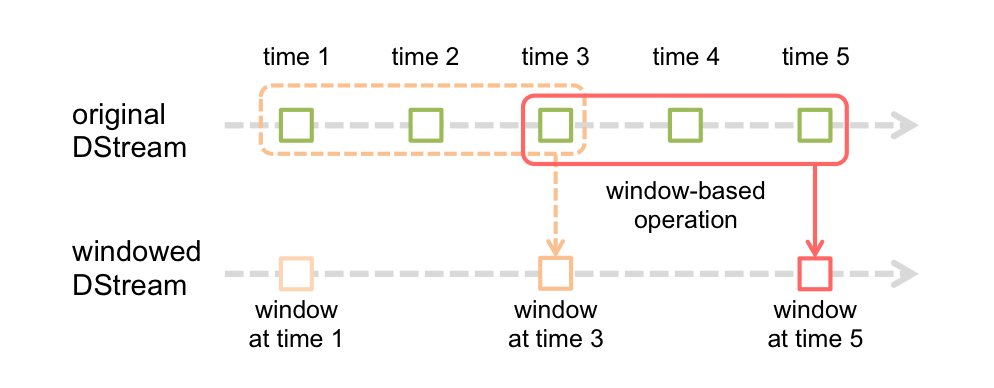
上面这个是官方的例子,每个窗口大小3个单元,滑动2个单元。这里的单元就是Dstream的批次间隔。每次滑动和大小都必须是单元的整倍数。举一个最简单的例子:countByWindow(windowLength,slideInterval)表示返回数据流在一个滑动窗口内的元素个数 。具体有哪些算子看手册好了。
还有一种算子是输出算子,就是将数据推送到外部系统的,比如print(),savaAsHadoopFiles()等。这里有一个比较有趣的是foreachRDD(func),表示该算子接收一个函数func,func将作用于DStream的每个RDD上。这个有一些使用的注意事项和例子,看手册吧
DStream生成的细节
到上面的了解程度其实Spark Streaming就可以用了,但是也就是能启动起来的程度,完全不知道数据怎么从哪些executor以什么形式进入spark engine。这一章就从原理层面讨论下这个问题。看的参考文献都是看源码分析的,但是我连spark源码都没看 ,看streaming有点远。。。
注:spark里面应该是有一个BlockManager的东西来管理rdd数据的分布,这个是属于spark的storage模块,这里就不展开了(主要我也不会 - -)。他是一个master-slave架构。这里结合对streaming的了解,猜测应该是实现了集群之间远程数据传输。
数据接收
启动spark streaming以后集群会选择一台executor作为某一个receiver的supervisor并标记为active状态。之后
- receiverSupervisor会启动对应的receiver。
- receiver会启动新线程接收数据,通过调用
ReceiverSupervisor.store一条一条接收。 - ReceiverSupervisor调用blockGenerator.addData进行数据填充,这里实际上是把数据存到一个ArrayBuffer[Any]的currentBuffer中。
把currentbuffer中的数据转化为数据块有两个BlockGenerator线程:
- 第一个线程定期地调用updateCurrentBuffer函数生成batch,然后将batch封装成block,时间是由spark.streaming.blockInterval参数配置的,默认是200ms。然后将生成的black放到一个blocksForPushing的队列里
- 第二个线程不断调用keepPushingBlocks函数从blocksForPushing里拿到blocks,然后调用pushBlock方法将Block储存到BlockManager中。
中间我就一直很奇怪Receiver的block最后写在哪里,感觉是写在本地很大,但是感觉写到其他机子上有很奇怪。直到找到stackoverflow这篇
One streaming batch corresponds to one RDD. That RDD will have n partitions, where n = batch interval / block interval. Let’s say you have the standard 200ms block interval and a batch interval of 2 seconds, then you will have 10 partitions. Blocks are created by a receiver, and each receiver is allocated in a host. So, those 10 partitions are in a single node and are replicated to a second node.
When the RDD is submitted for processing, the hosts running the task will read the data from that host. Tasks executing on the same node will have “NODE_LOCAL” locality, while tasks executing on other nodes will have “ANY” locality and will take longer.
其实数据就是写在receiver所在的那个机器,只不过rdd真正搞起来执行任务时其他executor可以从这个机器拿数据。至于rdd和block的关系,其实partition是一个逻辑分区的概念,对于的物理分区就是一个block。具体可以见这个文章

如何增加并行度
增加并行度有两个方法
- 优化里有讲一个参数
spark.streaming.blockInterval,是这只接收器的阻塞间隔。这个是生成block的时间间隔,时间越短block约多,对应rdd的partition也就越多 - 用多个Receiver去读取数据,操作的时候再union。
参考文献
这个文章问了搞清楚这个block查了很多东西,主要就是对spark还不熟,直接看streaming底层太费劲了
- Spark Streaming 数据产生与导入相关的内存分析:好文,对于block生成过程讲的比较清楚
- Spark(十一):Spark Streaming 原理剖析:另一篇将数据生成的文章
- Spark Streaming 执行流程:将streaming整体的一个东西
- CoolplaySpark/Spark Streaming 源码解析系列:广点通的讲spark streaming的一套
- shijinkui/spark_study:一个spark的资料
- Spark问题笔记2:讲spark一些基本概念,比如rdd和block关系的入门笔记
- Spark源码分析之-Storage模块:spark物理层存储的源码分析,比较深
- Four Things to Know About Reliable Spark Streaming with Typesafe and Databricks:一个讲容错的ppt,图画的不错。
本文采用创作共用保留署名-非商业-禁止演绎4.0国际许可证,欢迎转载,但转载请注明来自http://thousandhu.github.io,并保持转载后文章内容的完整。本人保留所有版权相关权利。
本文链接:http://thousandhu.github.io/2016/07/28/spark-streaming-数据结构分析/