概述
数据库CAP定理:一个分布式系统只能实现一致性,可用性和分区容忍性三个中的两个
1.4.5 P22
数据储存在HFile中,是经过排序的键值映射结构,文件内部由连续的块组成,块的索引信息放在文件尾部。每次打开Hfile时块先把索引load到内存,查找时通过块索引定位到块。
跟新数据先将数据提交到日志里(write-ahead log)。

- 1个regionServer包含一个WAL,一个blockCache和多个HRegion
- 1个region包含多个Store,每个Store对于一个column family
- 1个Store对于多个Storefile
- 1个storeFile对于1各Hfile
读取数据时先判断在那个region。确定region以后,有一个BlockCache(bloomfilter),先判断数据是否在memory里。队以一个hfile,他由多个64k的块组成,每个块有leaf index。leaf index的结尾组成组成一个intermediate index。对于每个block,还有自己的bloom,进一步在查找键值时filter。
- An In-Depth Look at the HBase Architecture
- Apache HBase I/O – HFile
- hbase存储结构-图-客户端读写数据顺序
- HBase实现分析:HFile
安装
|
|
其中第一个属性指定本机的hbase的存储目录,必须与Hadoop集群的core-site.xml文件配置保持一致;第二个属性指定hbase的运行模式,true代表全分布模式;第三个属性指定 Zookeeper 管理的机器,一般为奇数个;第四个属性是数据存放的路径。这里我使用的默认的 HBase 自带的 Zookeeper。同时在regionservers中写入regionserver,一行一个。
之后运行 bin/start-hbase.sh启动程序。
客户端api
curd
主要使用org.apache.hadoop.hbase.client的HTable类。由于HTable类需要扫描。meta表,所以尽量只创建一次,或者使用HTablePool
Put/Get/Delete 读写、删除数据,同时可以用table.setAutoFlush()设置是否使用缓冲区。p78
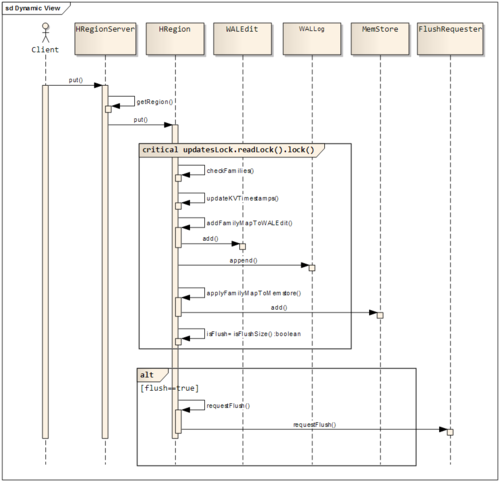
显示加锁 p111
|
|
get操作不需要锁,他用了一个多版本的并发控制机制保证行级别的读操作。get永远不会返回写了一半的数据。可以把它当做一个小规模的事务系统。
scan 提供扫描操作 p115
resultScanner类将扫描结果封装成迭代器,提供Result next(),close()等接口。 由于其很占用资源,要保证尽早关闭它。
filter
get和scan可以使用filter p130
- Rowfilter 行过滤器
- FamilyFilter 列族过滤器
- QualifierFilter 列名过滤器
- ValueFilter 值过滤器
- DependentColumnFilter 参考列过滤器
还有很多其他的过滤器用的时候再查吧
当需要同时使用多个需猎奇时,可以使用filterList(ListMUST_PASS_ONE,MUST_PASS_ALL
自定义filter需要实现filter接口或者直接继承filterBase类,同时要把它部署到所有regionserver上,并修改hbase-env.sh。p153
计数器
p160
|
|
计数器保证了操作的原子性,同时不需要锁,这比基于行级锁的单行修改方法要快。计数器不能用put初始化,储存方式不同,会造成错误
HTablePool p192
|
|
有相同conf的HTable共享一个HConnenction实例,这对于效率是有好处的(共享zookeeper链接,缓存通用资源)
客户端
rest
p322
|
|
rest同样有java客户端 p238
hbase shell p265。hbase支持利用管道运行命令:echo ”status" |bin/hbase shell。或者利用.rb文件。
shell支持for循环等复杂操作,因为shell基于jurby的IRB
|
|
文件
- 根级文件
- .logs: WAL文件
- 表级文件
- .tableinfo
- region文件
/<hbase-root-dir>/<tablename>/<encoded-regionname>/<col-family>/<filename>- .regioninfo
- .tmp:临时文件,比如hfile合并时产生的那些
- recovered.edits: WAL回放操作
除了regionServer挂掉然后在其他地方重启时,其他时候数据都是可用的(待确认)
合并
minor: 负责重写最后几个生成的文件导一个大文件。不会真正删除啥的。
major: 据说会将所有文件合并,并且进行真正的删除。major后一个store只有一个file
WAL写入流程(储存在hdfs中)
实现WAL的类是HLog,核心方法是append(),是否写入wal是可选的,通过调用setWriteToWAL(false)即可。这一段可以以后结合着看看源代码,主要讲了每个类干什么 p320
一个regionServer的WAL写到同一个log文件,而不是每个region单独写一个文件,主要原因是每个单独写的话存在磁盘寻道问题,是并发的写到磁盘不同位置,而写到一个就是一个顺序写。这是的一个服务崩溃以后无法立即重启的主要原因,崩溃regionserver的log需要拆分,即重新读取混合在一起的日志并将其按照归属的region分组。
get读取数据是首先用时间戳和bloom filter找到需要读取的StoreFile,然后便利他们和memstore,同时使用一个keyValueHeap类来扫描。~推测其得到的数据是按照堆的形式来储存~。他是按照时间降序来扫描的,因为sFile其实是时间有序的。这里有空可以看看代码(p327)。
如何获得数据的Region地址
首先, HBase内部维护着两个元数据表,分别是-ROOT- 和 .META. 表 他们分别维护者当前集群所有region 的列表、状态和位置。-ROOT-表包含.META.表的region 列表,因为.META. 表可能会因为超过region的大小而进行分裂,所以-ROOT-才会保存.META.表的region索引,-ROOT-表是不会分裂的。而.META. 表中则包含所有用户region(user-space region)的列表。表中的项使用region 名作为键。region名由所属的表名、region的起始行、创建的时间 以及对其整体进行MD5 hash值。
由于region的位置其实不是经常变动,所以会有缓存。具体访问步骤如下:
- 从缓存中得到region的位置(1次)
- 如果1中的位置失败,则从缓存中得到对应的.meta表的server,读取region(2次)
- 如果2中得到的region位置失败则从缓存找到root的server并读取。meta。的位置(1次)
- 如果成功,进入4
- 如果失败,则去zk读取root表的位置,然后再读取meta的位置(2次)
4,从meta得到region位置并读取。(1次)
主从复制
客户端将数据写入(Put)到的Region中,RegionServer会将这次写转换为一个WAL日志(附上自己的ClusterUUID),每个WAL日志中包含了若干个KV(视写入的column多少而定),并将这个WAL日志追加到全局的HLog中。Master端有一个ReplicationSource线程不断的去获取HLog的数据,并将新的数据写入到本地的一个Buffer(默认64M)中。当Buffer满了或者HLog无新数据的时候,ReplicationSource就向从集群的一个RegionServer发送同步的RPC请求。从集群的有一个ReplicationSink线程来同步接受Source传过来的数据,并将数据按照不同的表写到不同的本地Buffer中,然后由本地程序通过HTableClient端写入到本地的从HBase集群中。
这个过程中有几个要注意的问题:
1)Master如何选择从RegionServer的机器?
在复制启动的时候,从集群会将自己的ZK地址注册给主集群。Master通过从集群的ZK知道从集群有多少RegionServer,并从中随机挑出10%的RS用于复制。由于不同的Master会挑选不同的10%的机器,因此可以认为主集群的复制压力会大致均匀的分布到从集群的每台RegionServer上。
2)多个从集群复制的时候是如何不相互干扰的?
Master会为每个从集群创建一个ReplicationSource线程来复制数据,但是由于各个从集群复制的速度不一样。每个Source都需要维护一个上次同步的HLog的位置。各个Source用这个位置来同步不同的HLog片段的数据到不同的集群中。在完成复制的时候,Master还会向Zookeeper报告各个集群目前同步到哪个位置了。
3)在机器宕机的情况下如何继续复制?
分为两种情况,当从集群中正在复制的RegionServer宕机后,主集群的Master会选择另外一个备选的RegionServer进行复制。
当主集群的某个RegionServer宕机后,该集群中的其他的RegionServer会从Zookeeper上感知到这点,并接管该RegionServer的复制任务,将剩余的HLog数据复制到对应的从集群中。
http://www.fireflies.me/2014/02/%E4%BA%94%E3%80%81hbase-replication/
行键设计
hbase储存数据的最小单元是keyValue。他的结构是行键|列族|列限定符|时间戳|值。这表示每个单元都需要储存行键和列族。设计列族可以有效的减少储存文件。查询的筛选效率是从左到右递减的,所以将筛选信息放在行或者列族中会比较有效。
行键如果是按照一定形式组织的,很容易造成热点问题。而如果纯随机,则很难进行顺序读。因此常使用hash+信息(如时间戳)的方式。行键的设计需要考虑业务需求。这里有一篇参考
Avro和Protocol Buffer可以帮助hbase序列化存储数据
bloom filter
p355
通常设置错误肯定答复为1%
是否使用bloom filter
- 如果用户定期修改所有行,那么大部分储存文件都将包含用户查找的行数据,这种情况不适用于bloom filter。而如果用户批量更新,每行数据只出现在少数文件中,则bloom filter很有用。
- bloom filter会占用额外的空间。使用bloom filter以后每个storeFilte会跟一个bloom filter。每项一般在过滤器中占用1个字节,所以原来每项占的储存空间越大,bloom filter的额外空间占比越小。
- 是否使用行+列级的filter,取决于访问模式一般是整行访问更新还是会有某一列的更新
版本控制器
不同regionserver的时间可能不一致,这会导致数据的时间戳不一致,进而导致版本错误。用客户端时间覆盖服务器时间课余有效的解决这个问题。
p363有问题,删除时时间戳的关系
优化
第一点就是选择合适的压缩,一般是snappy
第二个是jvm调优,p393. jvm在gc时会导致程序暂停,gc的东西见这一篇
第三个就是region的拆分和移动,同时要注意对rowkey的设置
客户端api 最佳实践
- 禁止自动刷写
- 使用扫描缓存
- 限定扫描范围
- 关闭resultScanner
- 块缓存用法:如果是扫描操作,则应该setCacheBlocks为false。对于频繁访问某些行的操作,则为ture
- 优化获取行健的方式:使用filter
本文采用创作共用保留署名-非商业-禁止演绎4.0国际许可证,欢迎转载,但转载请注明来自http://thousandhu.github.io,并保持转载后文章内容的完整。本人保留所有版权相关权利。